News Scraping
Contents
News Scraping#
import requests
from bs4 import BeautifulSoup, Tag
from datetime import datetime
Search Google by URL#
When typing something into Google’s search bar, essentially we are creating a URL which leads to a website. For example, the following URL will lead to the webpage that we can reach by typing the word apple into the search bar.
GOOGLE = "https://www.google.com"
Note that we can so much more than just search based on a string (search bar input), which is basically what we usually do. In addition, we can add parameters to the URL so that more constraints on our search are specified. For example, we can search news within a particular date range.
We refer to this link for some detailed information about Googles search URL request parameters.
Some parameters of interest:
tbm, TBM (Term By Method), e.g.,tbm=nwswill search for newstbs, TBS (Term By Search), e.g.,tbs=cdr:1,cd_min:3/2/1984,cd_max:6/5/1987specifies a range from March 2, 1984, to June 5, 1987tbs=sbd:0sorts the results by relevancy
lr, language, e.g.lr=lang_enfor Englishlr=lang_zh-CNfor Chinese
Tip
Different parameters are connected with & symbol.
def create_search_url(query: str, date_str: str) -> str:
"""Create a Google search URL based on provided query content and date.
Parameters
----------
query (str): The text typed into the search bar.
date_str (str): Date string with format "YYYY-mm-dd".
Returns
-------
str: Search URL.
"""
# base URL
url = GOOGLE
# search content
url += f"/search?q={query}"
# search for news
url += f"&tbm=nws"
# get correct date format and then search by date
date = datetime.strptime(date_str, "%Y-%m-%d")
query_date_str = datetime.strftime(date, "%m/%d/%Y")
url += f"&tbs=cdr:1,cd_min:{query_date_str},cd_max:{query_date_str}"
# sort by relevancy
url += f",sbd:0"
# we want results in english
url += "&lr=lang_en"
return url
If we want to search news about Tesla on September 1, 2022, then the URL is:
url = create_search_url("Tesla", "2022-10-1")
url
'https://www.google.com/search?q=Tesla&tbm=nws&tbs=cdr:1,cd_min:10/01/2022,cd_max:10/01/2022,sbd:0&lr=lang_en'
Find Links to Webpages#
We can use function requests.get to request the content of a website.
Tip
Always remember to add a header to pretend to be a browser, otherwise your request may be denied.
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:106.0) Gecko/20100101 Firefox/106.0"
}
res = requests.get(url, headers=headers)
res
<Response [200]>
The return code 200 means that the request is successful. Alternatively, we can check this by examining whether res.ok is True:
res.ok
True
Parse the raw HTML content using bs4.BeautifulSoup:
soup = BeautifulSoup(res.content, "html.parser")
By observing the HTML structure of the Google search page, we find that all links are contained inside tags with class=SoaBEf. And these tags are decedents of a tag with id=search.
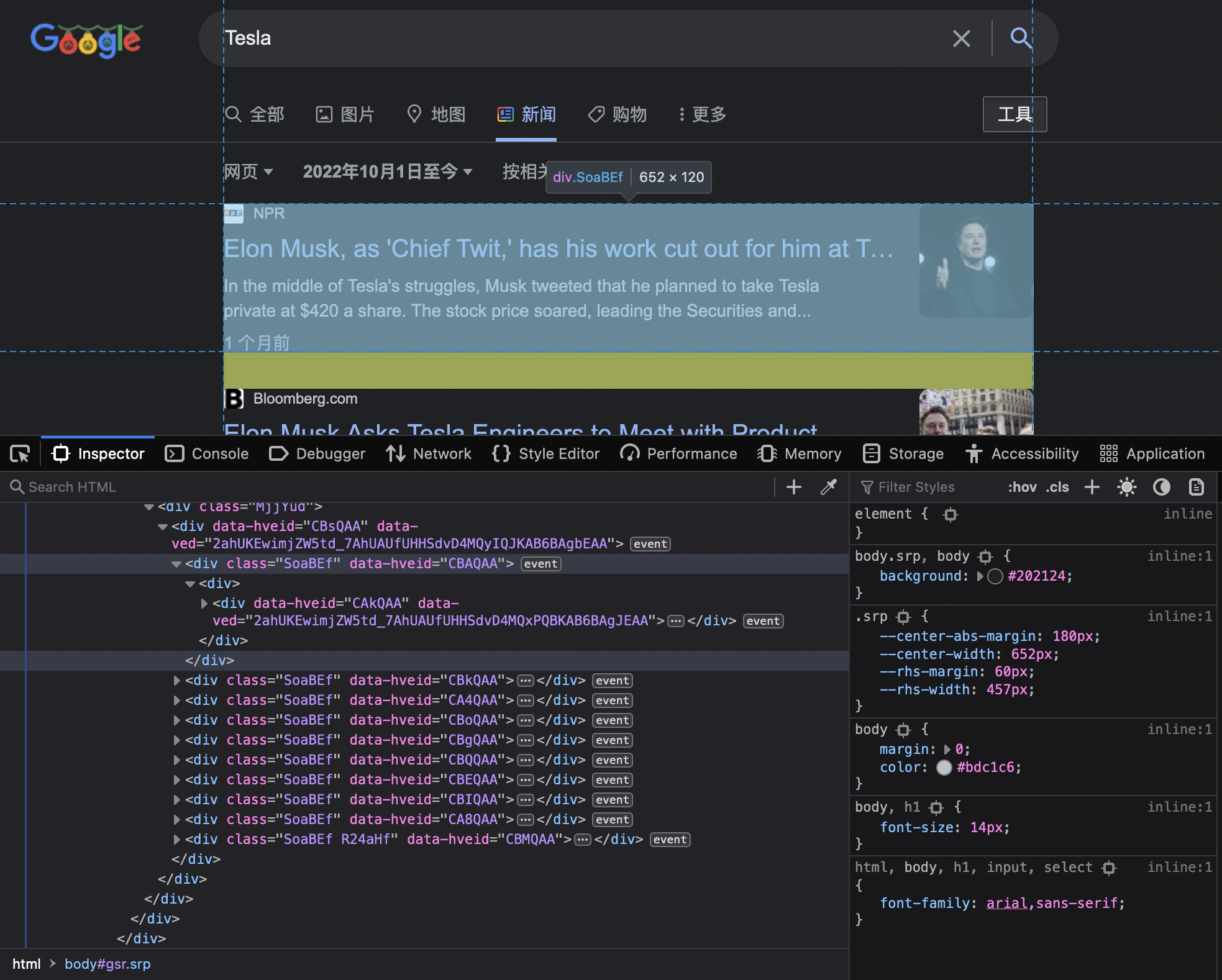
# find search tag
search_tag = soup.find(id="search")
# find tags containing links to webpages
tags = search_tag.find_all(attrs={"class": "SoaBEf"})
# extract links
links = []
tag: Tag
for tag in tags:
inner_tag: Tag = tag.find("a")
link = inner_tag.get("href")
links.append(link)
links
['https://www.bbc.com/news/technology-63100636',
'https://www.marca.com/en/technology/2022/10/01/63382cea46163f6e848b4596.html',
'https://spectrum.ieee.org/tesla-optimus-robot',
'https://cnnespanol.cnn.com/2022/10/01/robot-tesla-dia-inteligencia-artificial-trax/',
'https://www.siasat.com/tesla-now-has-160000-customers-running-fsd-software-musk-2425130/',
'https://www.journaldemontreal.com/2022/10/01/elon-musk-presente-lambitieux-robot-humanoide-de-tesla',
'https://www.barrons.com/articles/tesla-nio-li-xpeng-deliveries-51664633994',
'https://www.fool.com/investing/2022/10/01/better-stock-split-stock-to-buy-tesla-or-shopify/',
'https://www.slashgear.com/1034404/tesla-model-3-vs-polestar-2-which-is-the-better-electric-car/',
'https://www.mundodeportivo.com/urbantecno/ciencia/una-rutina-de-ejercicio-estando-sentado-y-con-el-minimo-esfuerzo-la-ciencia-ha-conseguido-hacerlo-posible']
Scrape Headlines#
Now, we want to access each webpage via its link and scrape its heading (news headline).
link = links[0]
res = requests.get(link, headers=headers)
res.ok
True
Make another soup for the webpage:
webpage_soup = BeautifulSoup(res.content, "html.parser")
Tip
For most of webpages, the first level heading is contained in a special tag named <h1>.
headline_tag: Tag = webpage_soup.find("h1")
headline = headline_tag.text
# strip whitespaces and line breaks
headline = headline.strip()
headline
'Tesla boss Elon Musk presents humanoid robot Optimus'
Command Line Usage#
In our command line app main.py, we have implemented a command find-company-new. The help message is as follows.
> python main.py find-company-news --help
Usage: main.py find-company-news [OPTIONS]
Find news headlines for the specified company.
Options:
-c, --company TEXT Company stock/ticker symbol. [required]
-q, --query TEXT Search query for the news. [required]
-a, --from-date TEXT Starting date.
-b, --to-date TEXT Ending date.
-s, --skip INTEGER Number of links to skip. [default: 0]
-f, --force Whether to find headline even if news data exists.
--help Show this message and exit.
For example, we can find the news for Tesla from October 1, 2022, to October 5, 2022, like so:
> python main.py find-company-news --company TSLA --query "Tesla" --from-date "2022-10-1" --to-date "2022-10-5" --force
Start finding news headlines...
News on 2022-10-01: Tesla boss Elon Musk presents humanoid robot Optimus
News on 2022-10-02: Tesla blames logistics problems after delivering fewer cars than forecast
News on 2022-10-03: Tesla slides on widening delivery and production gap, demand worries
News on 2022-10-04: A Musk Retweet: Tesla CEO Says He'll Pay $44 Billion to Buy Twitter
News on 2022-10-05: Musk's move to close Twitter deal leaves Tesla investors worried
Successfully found all the news for TSLA.